Oysaki sıradan makine öğrenmesi programları basit insan diliyle eğitildiklerinde, belli ifade kalıplarına gömülmüş kültürel ön yargılara sahip olabiliyor. Bu ön yargılar, çiçekleri böceklere tercih etmekten; ırk ve toplumsal cinsiyet konularında tatsız görüşlere sahip olmaya kadar geniş bir yelpazeye uzanabilir.
Online metin araması yapmak veya otomatik çeviri sistemlerini kullanmak doğal dilin işlenerek bilgisayarlara aktarılmasına birer örnektir. Makine öğrenmesindeki olası ön yargıların ele alınması, iletişimin bu şekilde sağlanmaya başlanmasıyla birlikte önemli hale geliyor.
Princeton Üniversitesi Bilgi Teknolojileri Politikaları Merkezi’nde ve Stanford Hukuk Okulu İnternet ve Toplum Merkezi’nde çalışmalar yapan Arvind Narayanan ,”Makine öğrenmesindeki adalet ve ön yargılara dair sorular toplum için muazzam derecede önemlidir.” diyor.
Princeton Üniversitesi’nden Aylin Çalışkan önderliğinde yazılan, "Dil korpusundan otomatik olarak türetilen anlambilim, insana benzer ön yargılar içerir” isimli bu çalışmaya ilişkin makale Science dergisinde 14 Nisan 2017’de yayınlandı.
Çalışmada, 1990’larda Washington Üniversitesi’nde geliştirilmesinden sonra pek çok sosyal psikoloji çalışmasında kullanılan Örtük Çağrışım Testi’ne başvuruldu. Bu test, katılımcıların bir bilgisayar ekranında görüntülenen kelimeleri eşleştirme sürelerini (milisaniye cinsinden) ölçen bir testtir. Örtük Çağrışım Testi defalarca gösterildiğindeyse, katılımcıların benzer kavram çiftlerini bulma süresi; farklı olduğunu düşündükleri iki kavramı eşleştirme sürelerine oranla daha kısadır.
Örneğin, çiçeklerden “gül” ve “papatya”; böceklerdense “karınca” ve “güve” kelimelerini ele alalım. Bu kelimeler, hızlı bir şekilde “sarılmak” ve “sevmek” gibi güzel; ya da “pis” ve “çirkin” gibi hoş olmayan kavramlarla eşleştirilebilir.
Princeton ekibi, Örtük Çağrışım Testi’nin makine öğrenmesi sürümü sayılabilecek GloVe adlı programı kullanarak bir deney tasarladı. Program, Stanford Üniversitesi’nden araştırmacılar tarafından geliştirilen popüler, açık kaynaklı ve bir start-up bir makine öğrenmesi şirketinin temel olarak kullanacağı cinsten bir programdır. GloVe algoritması –örneğin- 10 kelime penceresinden oluşan bir metindeki kelimelerin eşdizim istatistiğini betimler. Birbirine sıkça yakın beliren kelimeler arasındaki çağrışım, nadiren yakın belirenlere oranla daha fazladır.
GloVe, Stanford araştırmacıları tarafından 840 milyar kelime içeren dünya çapındaki internet ağında bulunan büyük içerik trolüne bırakıldı. Yazılı insan kültürünün bu büyük örneklem kümesinde, Narayanan ve meslektaşları “bilgisayar programcısı, mühendis, bilim insanı” ve “hemşire, öğretmen, kütüphaneci” gibi kelimeleri; “adam, erkek” ve “kadın, dişi” gibi iki niteleyici kelime seti ile birlikte incelediler. Amaçları ise insanların farkında olmadan sahip olabileceği türden ön yargılara dair kanıtlar bulmaktı.
Elde ettikleri sonuçlarda çiçekleri böceklere tercih etmek gibi masum ve zararsız ön yargılar çıktığı gibi; toplumsal cinsiyet ve ırk sınırlarındaki ön yargıları içeren örnekler de vardı. Princeton makine öğrenmesi deneyi, uzun yıllardır insanlara ait temalara dayanan Örtük Çağrışım Testi çalışmalarında bulunan ön yargının ispatını gerçekleştirebilmişti.
Örneğin; makine öğrenmesi programı kadın isimlerini daha ziyade aileye atıfta bulunan “anne-baba” ve ”düğün” gibi kelimelerle eşleştirmişti. Erkek isimlerini ise, kariyer ile ilişkilendirilen “profesyonel” ve ”maaş” gibi kelimelerle. Tabii ki, bunun gibi sonuçlar gerçeğin ve cinsiyetler arası eşit dağılmayan meslek tiplerinin sadece objektif bir yansımasıdır.
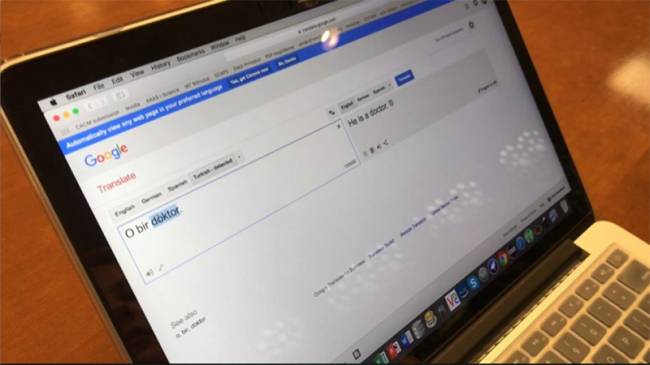
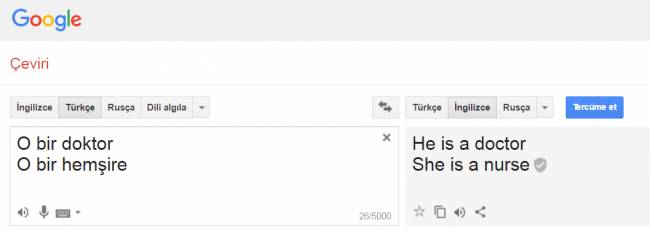
Bununla birlikte meslekler hakkındaki bu ön yargı, olumsuz cinsiyetçi etkilere neden olabilir. Mesela yabancı diller, makine öğrenmesi programları tarafından naifçe işlendiğinde bu programlar toplumsal cinsiyet kalıplarına uygun cümleler oluşturur. Türkçe ’de üçüncü kişi (“o”) zamiri cinsiyetsizdir. Hepimizin bildiği çeviri servisi Google Çeviri ’ye "O bir doktor." ve "O bir hemşire." cümleleri yazıldığında, İngilizce ’ye "He is a doctor." ve "She is a nurse." şeklinde çevriliyor.
Diğer bir hoş olmayan örnek ise, 2014’te Harvard Üniversitesi’nden Sendhil Mullainathan’a ve Chicago Üniversitesi’nden Marianne Bertrand’a ait bir makalede geçiyor. Araştırmacılar; 1300 iş ilanına 5000 adet aynı özgeçmişi, yalnız başvuran kişinin adını Avro-Amerikan ya da Afro-Amerikan olacak şekilde değiştirerek gönderdiler. İlk grup ikinciye oranla % 50 daha fazla mülakata çağrıldı. Princeton ekibinin yeni çalışması ise, bu ön yargıyı doğrulayacak şekilde Afro-Amerikan isimlerinin Avro-Amerikan isimlerinden daha kötü çağrışımlar yaptığını ispatladı.
Bilgisayar programcıları, yapay zekâ sistemlerinin altında yatan makine öğrenmesi programlarını açık ve matematik temelli geliştirerek belli kültürel stereotipleştirmelerin önüne geçebilirler. Anne babalar ve danışmanların çocuklarda ve öğrencilerde adalet ve eşitlik kavramlarını aşılamaya çalışmaları gibi; kod yazanlar da makinelerin insan doğasının iyi taraflarını yansıtmalarına yardımcı olabilir.
Kaynak
Princeton University, Engineering School. "Biased bots: Human prejudices sneak into artificial intelligence systems." ScienceDaily. ScienceDaily, 13 April 2017.
www.sciencedaily.com/releases/2017/04/170413141055.htm
Çalışmaya ait yayınlanmış makale:
Aylin Caliskan, Joanna J. Bryson, Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science, April 2017 DOI: 10.1126/science.aal4230
Konuyla ilgili ek okumalar:
“Tabula rasa robot Tay ve Twitter’da Cinsiyetçilik”. http://catlakzemin.com/tabula-rasa-robot-tay-ve-twitterda-cinsiyetcilik-2/
“Zo ve depolitize edilmiş zekası”. http://catlakzemin.com/zo-depolitize-edilmis-zekasi/

En Son Yazılar








![Uzay Çalışmalarının Önemi - Süleyman Fişek [Röportaj]](https://fizikist.com/uploads/img/uzay-calismalarinin-onemi.jpg "Uzay Çalışmalarının Önemi - Süleyman Fişek [Röportaj]")




Fizikist © Copyright 2008 - 2026
0 yorum